Uber 机器学习平台实践
前言
本文是「算法工程化实践选读」系列的第 2 篇,选读 Uber 在 2017 年 9 月发布的技术博客 Meet Michelangelo: Uber’s Machine Learning Platform [1]。它介绍了机器学习平台 Michelangelo(意大利文艺复兴时期伟大的绘画家、雕塑家、建筑师和诗人)的各个组件的职能,第一次细致地向大家描述了机器学习平台应有的全貌。
现状和问题
Uber 有众多业务线,其中包含许多使用 ML 的场景,例如:共享出行 App 需要用算法预测乘客的到达时间、送餐 App 需要用算法为用户按照个人喜好为餐馆排序、客服中心需要用算法减少人工客服的介入,等等。多个业务线为了快速满足使用 ML 的需求,很自然地采了烟囱式的架构,逐渐产生了系统难以维护、模型难以上线等问题,亟需统一的解决方案来涵盖 ML 的全流程。
为了系统地解决问题,Michelangelo 平台(以下简称平台)首先厘清并定义了 ML 的全流程——数据管理、模型训练、模型评估、模型部署、做出预测、预测监控,并给出了各环节的解决方案。下文讨论平台在各个环节的做法。为了便于讨论,下图展示了平台的全景,会在后文被反复引用。
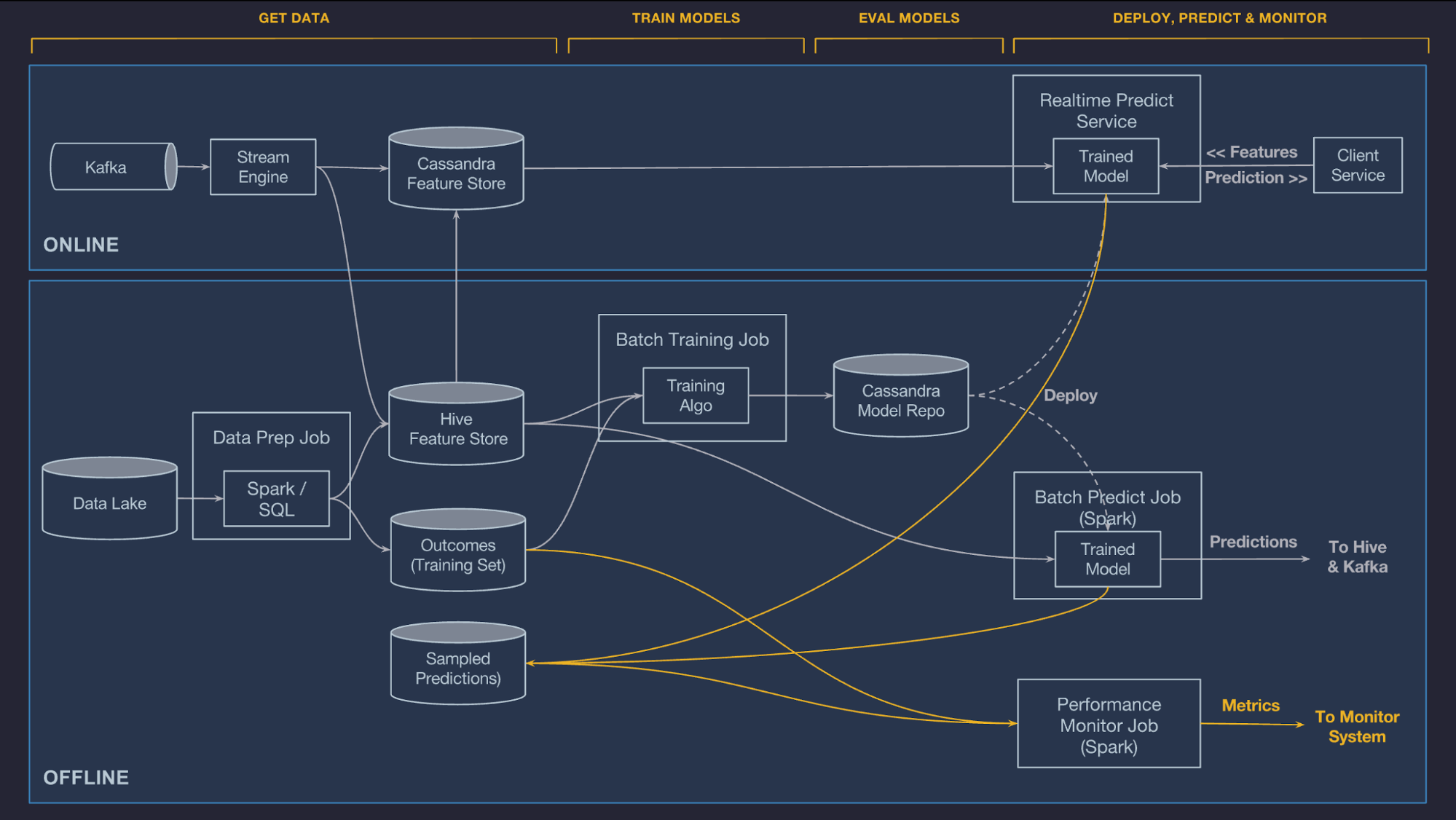
数据管理
数据是 ML 中最难的部分。平台的数据管理组件包括特征生成管道和特征仓库。
特征生成管道(Stream Engine 和 Data Prep Job)经工作流引擎的调度,从 Kafka 流数据源 和 Data Lake 批数据源读取数据,转换成供 ML 模型使用的特征,写入特征仓库(Cassandra Feature Store 和 Hive Feature Store)。一旦特征落库,就可以供在线预测(Realtime Predict Service)、离线训练(Batch Training Job)和离线预测(Batch Predict Job)使用。
值得一提的是,为了简化特征生成管道的实现,平台内置了一套基于 Scala 的 DSL,支持声明式地定义逻辑,而无需编写 Samza(注:平台在 2019 年之前已经把逻辑迁移到 Flink)和 Spark 代码。平台后续开发的 PyML 支持直接调用 Python 库,编写 Python 代码,进一步简化了特征生成管道的实现。
这样的架构有什么好处?
- 特征生成管道是把数据加工为特征的唯一指定地点,避免因逻辑散落各处(训练、预测)而造成的错误。
- 特征仓库作为联系数据和模型的桥梁,让不同团队分工明确。
- 集中的特征仓库使得特征的发现和共享成为可能,避免不同业务线重复开发和维护特征生成管道,这对于 Uber 业务线众多的现状十分重要。
模型训练
模型训练是一个高度交互的过程。平台支持算法工程师在最为熟悉的 Jupyter Notebook 环境中,通过调用 Python SDK 完成模型训练的全过程。
- 定义模型。算法工程师需要在模型配置中,声明模型类型(需要在平台的支持列表内)、超参数(平台支持超参数搜索)、数据源、特征生成管道 DSL、计算资源要求(机器数量、内存大小、是否使用 GPU 等)。
- 触发训练。触发后,工作流引擎执行训练任务。
- 存储训练结果。训练完成后,评估报告(P-R 曲线和 ROC 曲线)、模型配置和模型参数会被上传到模型仓库(Cassandra Model Repo),用于分析和部署。
模型训练注重迭代,因此训练效率十分重要。平台通过 Data Science Workbench 满足算法工程师的不同训练需求:在 GPU 集群上分布式训练深度学习模型、在 CPU 集群上训练树和线性模型、在普通 Python 环境下实验各种不同模型。平台还针对深度学习的训练提供额外支持,见 Horovod。
模型评估
在得到理想模型之前,算法工程师往往需要训练很多个模型,记录、评估、比较这些模型会为算法工程师提供很多有用的信息。平台在基于 Cassandra 的模型仓库中记录详尽的模型元数据,包括:
- 训练发起人。
- 训练工作流的起止时间。
- 模型配置。
- 使用的训练和验证数据集。
- 每个特征的分布。
- 模型准确度指标。
- 常用图表,如 ROC、P-R、confusion matrix。
- 习得参数。
- 模型可视化。
模型部署
平台支持通过 CLI 和 UI 快捷地部署模型。部署所需的模型 artifacts(包括元数据、模型参数文件,和编译过的特征生成 DSL)被打包成 ZIP,传送到指定服务器。预测服务会重载模型,重新开始处理预测请求。
做出预测
平台支持在线和离线预测。
对于在线预测,在模型部署完成后,在线预测服务已经将预测所需的模型从模型仓库中载入到内存中。一旦在线预测服务收到从客户端发来的包含 entity ID 的预测请求,它首先通过 entity ID 从在线特征仓库获取对应的特征向量,然后将特征向量输入模型,计算出预测值,返回给客户端。预测服务使用 Java 开发,以实现高并发和低延迟。
对于离线预测,工作流将模型载入工作流的内存,从离线特征仓库中批量读取特征并作出预测,将预测值写入 Hive 或 Kafka。
预测监控
训练中表现优秀的模型在生产环境中可能会错得离谱,因此平台支持对模型的预测进行细致的监控。最有效的办法是在生产环境中打印出一定比例的预测日志,并在稍后与观测值进行 join 和比较。另一种办法是记录下预测值的分布。
总结
Uber 团队在开发 Michelangelo 的过程中总结出三点重要经验。
从小做起,快速迭代。从范围最小、影响力最大的切入点做起,容易出成果,获得领导层支持,有利于后续的快速迭代。在初期,平台专注于支持大规模的离线训练和离线预测。随后,逐渐支持特征仓库、模型评估、在线预测服务、深度学习、Jupyter Notebook 集成、partitioned models 等。
让工程师使用最趁手的工具。在平台的早期,外部用户还不多,开发的主力是平台工程师,使用 Spark / Spark ML / Scala / Java 这个技术栈有利于快速迭代。但当平台愈发成熟,平台的重点变为快速的模型试错和迭代,该阶段的开发主力是算法工程师,他们可能需要定制化地在不同环节增加对某些模型的支持,例如实现未被内置支持的数据预处理、实现对新的深度学习模型分布式训练的支持等,这时他们希望能使用熟悉的 TensorFlow / PyTorch / Python / Jupyter Notebook 进行开发。PyML 正是这方面的尝试。
数据是 ML 系统最重要,但也是最难的部分。难体现在技术和人两方面。在技术的方面,每个公司都有一套运行多年的数据仓库、数据管道、工作流系统,其中可能存在各种不尽完善之处,导致在接入 ML 平台后难以应对频繁和快速的变化。在人的方面,取数的需求由算法工程师提出,由数据工程师实现,跨部门、跨工作语言(JVM vs. Python)的合作通常不易。特征仓库这个抽象层正是为了解决这个问题而提出的,详情可参见平台的特征仓库 Palette。
Uber 通过丰富的业务实践,沉淀出一个成熟的 ML 平台,并慷慨地通过技术博客、公开演讲和开源软件等形式,展现出平台在不同发展阶段的权衡、技术选型和着力点,让我们得以窥见一个成熟的 ML 平台的发展历程,对我们在伴鱼从零开始搭建 ML 平台有很大的借鉴意义。
参考文献
[1] Meet Michelangelo: Uber’s Machine Learning Platform. https://eng.uber.com/michelangelo-machine-learning-platform/
[2] Scaling Machine Learning at Uber with Michelangelo. https://eng.uber.com/scaling-michelangelo/
Feedback is a gift! Please send your feedback via email or Twitter.
© Yik San Chan. Built with Vercel and Nextra.