Practical MLSys Goodreads
Feature Store
What is a Feature Store
Link. By Mike Del Balso at Tecton and Willem Pienaar at Feast, 2020/10.
The post introduces a coherent conceptual framework to understand what make a feature store. I will use it as a starting point and refer to it as "Feast-architecture" or "Feast's" from here on, so please READ THIS FIRST.
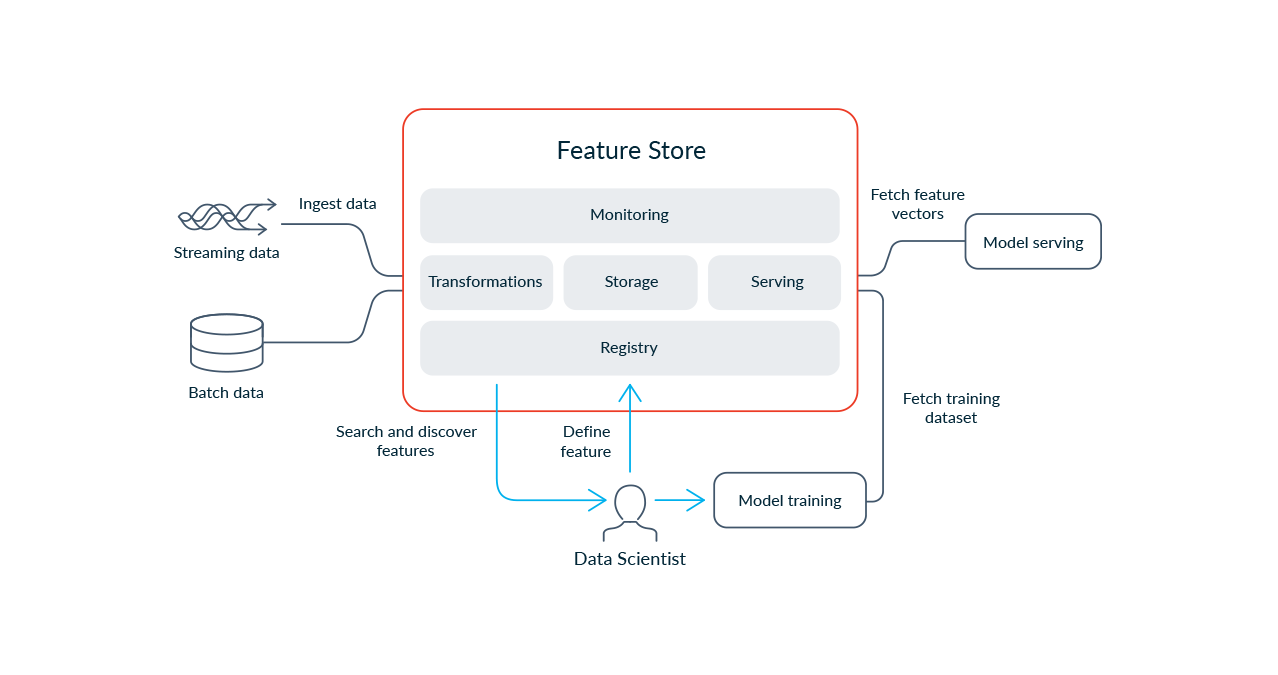
Rethinking Feature Stores
Link. By Chang She at Tubi, 2019/07.
The post asks a good question as quoted below. Luckily it is partially answered in the Tecton post.
I've found it difficult to think about these existing systems coherently. In general the focus has been "well we needed to satisfy requirement X so we implemented Y in this way" (e.g., Ziplines backfilling, Michelangelo's online store, etc). But I haven't really seen a conceptual framework that truly helps us think about how all of these different pieces fit together. Without a coherent conceptual framework, the result seems to be that depending on what use case you decide to add or remove, the architecture to serve these use cases may look drastically different. For anyone trying to select or design a feature store, this is not very encouraging.
Building Riviera: A Declarative Real-Time Feature Engineering Framework
Link. By Allen Wang and Kunal Shah at DoorDash, 2021/03.
Riviera uses Flink SQL as DSL for feature engineering, because:
- It is a proven approach as shown by User's Michelangelo and Airbnb's Zipline.
- Flink SQL is mature enough with contributions from Uber, Alibaba, etc.
While Flink SQL is good at feature transformation logic, it is weird to define the underlying infrastructure with (think of the WITH ('connector' = 'kafka', 'properties.bootstrap.servers' = '...') section). YAML works great in this front (think of k8s). How users define the feature "total orders confirmed by a store in the last 30 minutes" in Riviera is shown as below. Once any user puts together a configuration as shown below, they can deploy a new Flink job using this application with minimal effort.
source: - type: kafka kafka: cluster: ${ENVIRONMENT} topic: store_events schema: proto-class: "com.doordash.timeline_events.StoreEvent"sinks: - name: feature-store-${ENVIRONMENT} redis-ttl: 1800compute: sql: >- SELECT store_id as st, COUNT(*) as saf_sp_p30mi_order_count_avg FROM store_events WHERE has_order_confirmation_data GROUP BY HOP(_time, INTERVAL '1' MINUTES, INTERVAL '30' MINUTES), store_idComments:
- The marriage of Flink SQL (for compute) and YAML (for infra) is beautiful.
- Everyone likes Protobuf, no? (Note the
proto-classfield above)
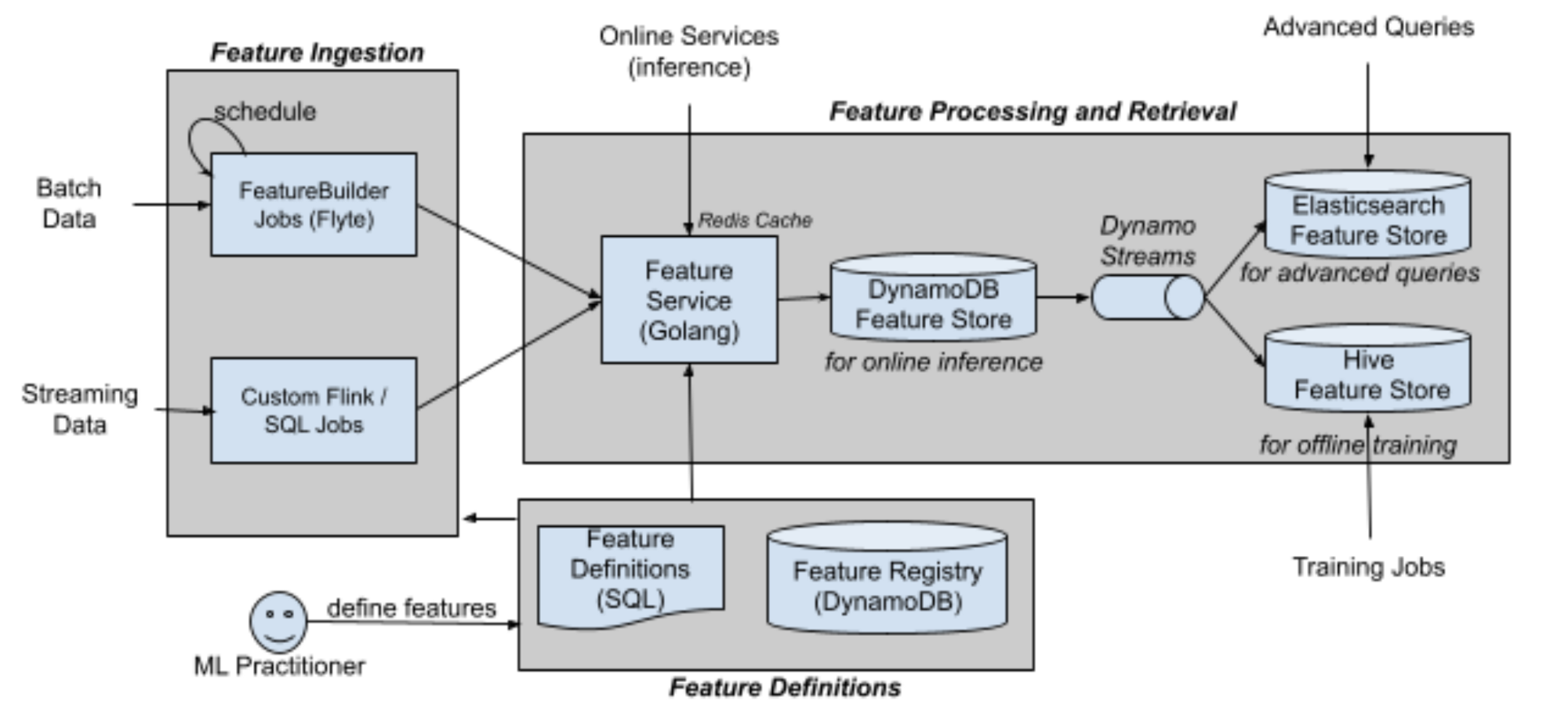
ML Feature Serving Infrastructure at Lyft
Link. By Vinay Kakade and Shiraz Zaman at Lyft, 2021/03.
Introduce how Lyft build feature store. The architecture is very similar to Feast's, with two noticeable differences:
- Ingestion: Offline feature store (Hive) writes data to the online feature store (DynamoDB) through Dynamo Streams (maybe CDC).
- Storage: Elasticsearch feature store is in place for advanced queries.
Comments:
- Ingestion: The CDC approach is very specific to the database in use.
- Storage: What are the advanced queries that ML practitioners do?
Building a Gigascale ML Feature Store with Redis, Binary Serialization, String Hashing, and Compression
Link. By Arbaz Khan and Zohaib Sibte Hassan at DoorDash, 2021/03.
DoorDash figures out an approach to store billions of feature-value pairs and handle millions of requests per second, both efficiently. Here's how.
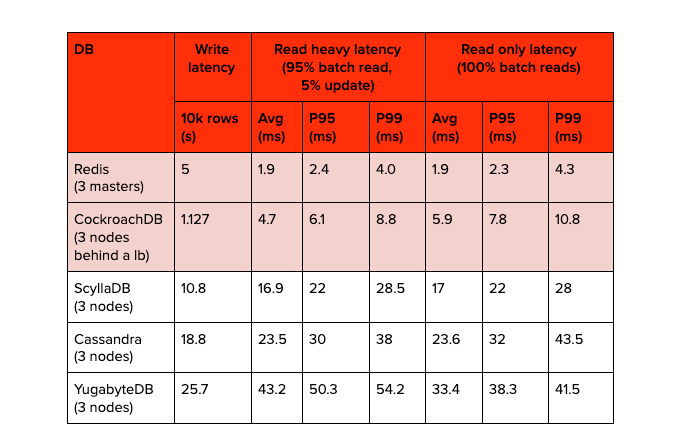
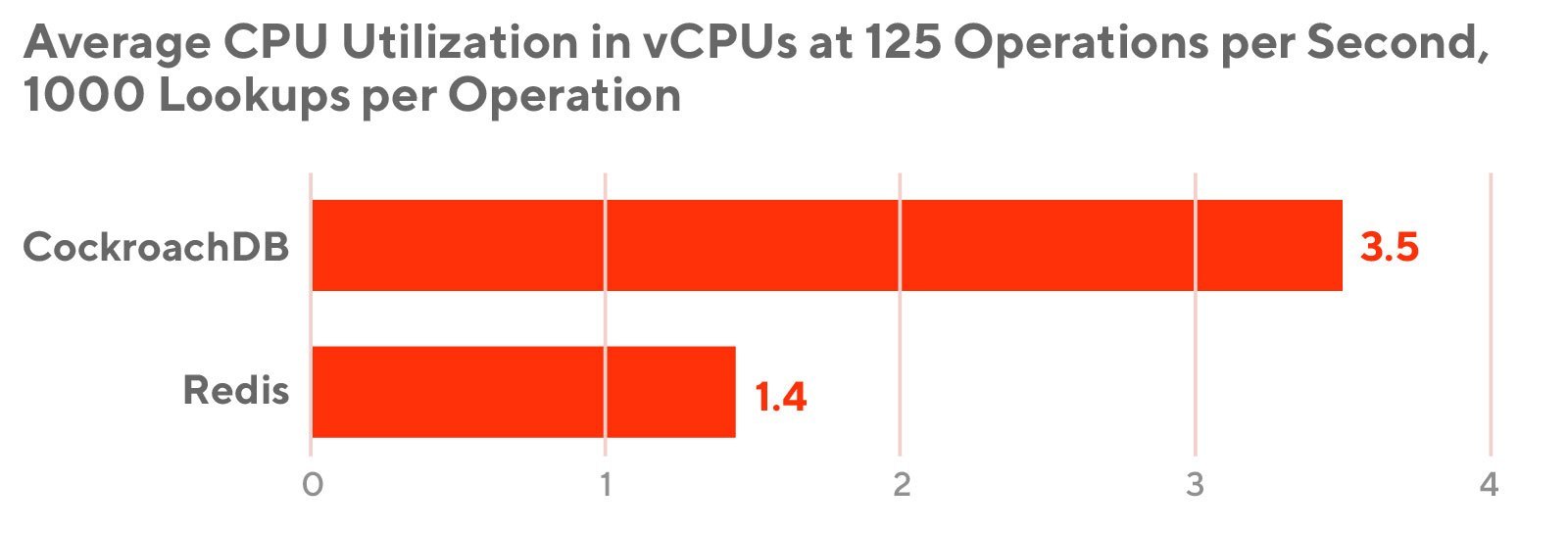
First, the team decides Redis has lowest read latency and CPU utilization after a YCSB benchmarking against Redis, CockroachDB, ScyllaDB, Cassandra and YugabyteDB.
Then, the team explores further optimizations to reduce Redis' memory footprint and CPU utilization:
- Store features as entity's Hash rather than a flat list of k-v pairs:
HSET entity_id feature_name feature_value. - Compress key using xxHash:
HSET entity_id XXHash32(feature_name) feature_value. - Store float values as plain string, and compress int lists with Snappy.
- Byte-encode (rather than compress) embeddings using protobuf.
AI/ML needs a Key-Value store, and Redis is not up to it
Link by Mikael Ronström and Jim Dowling at Logical Clocks, 2021/02.
Redis is a popular option for online feature storage (DoorDash, Feast, etc), but Logical Clocks challenges it. Mikael, creator of NDB Cluster, builds RonDB as an online feature storage option.
The post compares RonDB vs. Redis from 3 perspectives.
- Performance. This is where RonDB shines. With benchmarking, it claims lower latency, much higher throughput, availability and scalability provided RonDB's third-generation multithreaded architecture. It says Redis is still at the first generation.
- Database capabilities. RonDB supports transactions and SQL.
- User friendliness. NDB Cluster has an undeserved reputation of being challenging to configure and operate. RonDB overcomes this limitation by its presence on AWS and Azure.
My two-cents: it is always good to know more options, but I believe Redis can serve my use case very well for a very long period.
Maintaining Machine Learning Model Accuracy Through Monitoring
Link by Swaroop Chitlur and Kornel Csernai at DoorDash, 2021/05.
Model predictions tend to deviate from the expected distribution over time, due to the data pattern change. To overcome this, DoorDash builds integrity and autopilot into their feature store in the following steps:
- Log model prediction (sent_at : timestamp, prediction_id : string, predictor_name : string, model_id : string, features : key-value pairs, prediction_result : numerical, default_values_used : set of feature names).
- Collect them in data warehouse.
- Query the data warehouse and emit the statistical values (avg, stddev, min, max, and approx_percentile etc) as Prometheus metrics.
- Visualize the metrics in Grafana dashboard.
- Alert.
My two-cents: When it comes to monitoring, good-old software engineering serves ML well.
The Feature Store for AI
Link. By Chang She at Tubi, 2020/12.
Ask a good question: ML Tooling for unstructured data (images, videos, etc) has not caught up.
Comment: Activeloop allows users to read unstructured data just as a pandas.DataFrame, from multiple sources (s3 etc). Chang and friends are also working on rikai.
Feedback is a gift! Please send your feedback via email or Twitter.
© Yik San Chan. Built with Vercel and Nextra.