Lakehouse
This summary is based on the Lakehouse paper by Databricks. Many thanks to Ruben Berenguel's writing that helps me sort it out.
Data warehousing has evolved a lot, as shown in the following figure copied from the paper.
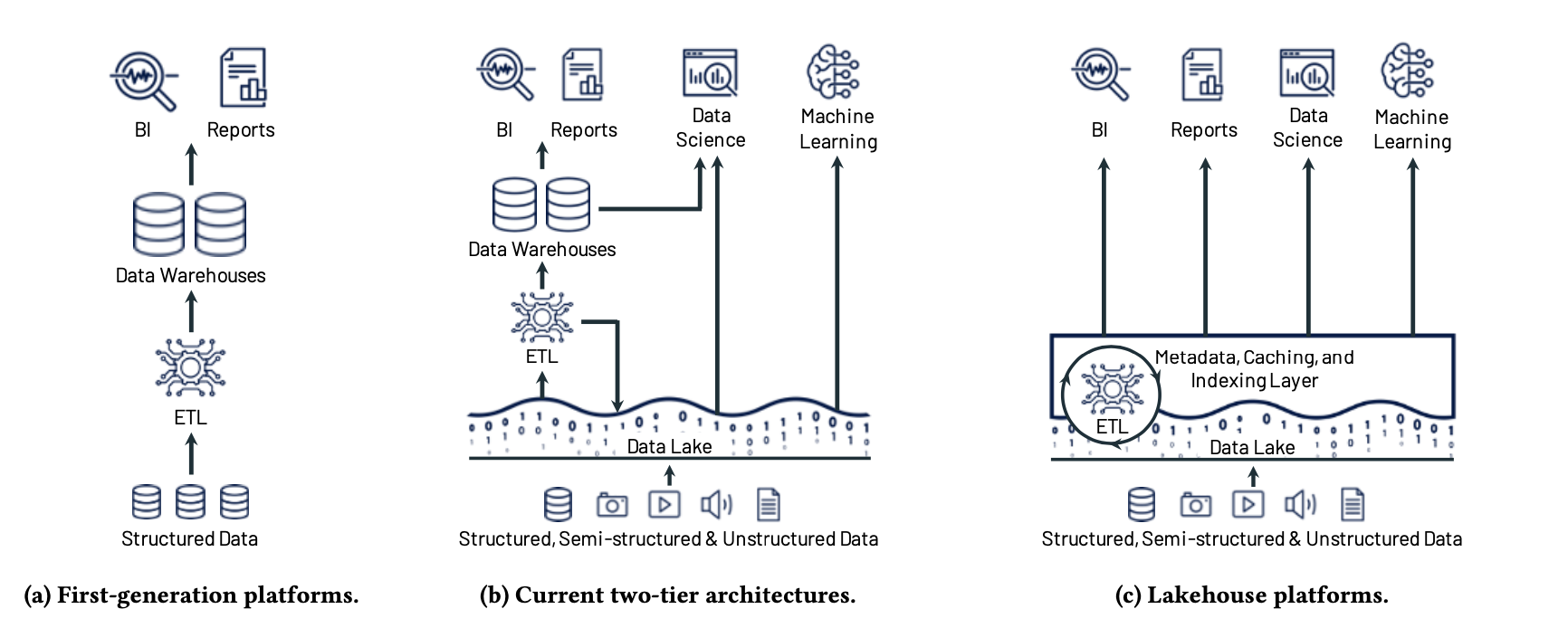
First Generation: Data Warehouses
Pros:
- Management features such as ACID transactions, data versioning, auditing.
- Performance features such as indexing, caching and query optimization.
Cons:
- Cannot access internal format.
- Cannot store unstructured data.
- Cannot handle data science or machine learning workloads - data is large compared to BI, need to process using non-SQL code, reading data via JDBC is slow
Second Generation: two-tier lake + warehouse architecture
Data first go to the lake, and then get synced to warehouses.
Pros:
- Lake provides low-cost and directly-accessible storage (previously HDFS, now S3) in open format (Parquet).
- Support unstructured data.
Cons:
- Lake loses management and performance features.
- Difficult to keep lake and warehouse data in sync.
- Data warehouse can run late in data.
- Duplicated storage between lake and warehouse.
Third generation: Lakehouse architecture
Best of both worlds! Here's how:
- Add a transactional metadata layer that supports management features.
- Implement performance optimizations:
- Indexing: (not discussed yet).
- Caching: use SSDs and RAM as the cache.
- Query optimization: record ordering.
Conclusion
Note that Lakehouse is more of a specification, while Delta Lake is an implementation by Databricks. Go check it out!
Feedback is a gift! Please send your feedback via email or Twitter.
© Yik San Chan. Built with Vercel and Nextra.