特征平台需求层次理论
前言
本文是「算法工程化实践选读」系列的第 1 篇,翻译 Eugene Yan 的技术博客 Feature Stores - A Hierarchy of Needs [1]。
出于开发伴鱼特征平台的需要,我最近阅读了很多关于特征平台的实践文章,但总有「一叶障目,不见泰山」之感——每个公司的算法工程化现状不尽相同,导致解决方案的侧重点不同,在架构上的区别也很大。正如我的前同事佘昶在他 2019 年的一篇文章中,到位地总结:我们缺乏一个系统性地思考特征平台的框架。[2]
幸运的是,选读的博客正好提供了这样一个思考框架,并将这个思考框架用于分析当前的各个特征平台上。我在征得 Eugene 的同意后,全文翻译,以飨中文读者。以下是译文。
特征平台(feature store)最近很火。2020 年 12 月,AWS 发布了 SageMaker 特征平台。上个月,大数据平台 Splice Machine 也发布了一款特征平台。Datanami 引用 Tecton.ai 联合创始人的话,称 2021 年为特征平台之年。
根据我们的经验,管理特征是机器学习上线最大的瓶颈之一。—— Uber
特征和标签是机器学习模型的输入。在回归中,标签是因变量,特征是自变量。在表格中,标签是我们想要预测的列,特征是除 ID 外的其它列。
大家对于「特征平台是什么」有很多种理解。有人把它简单地定义为「一个集中存储特征的地方」。也有人称特征平台能帮你「实现特征的一次创建,多处使用」或「百倍地提高模型部署效率」。之所以回答五花八门,是因为每个人想要特征平台做的事情都不同。
我研究了大量业界实践,试图理解特征平台在不同场景下解决的问题。受心理学家马斯洛的启发,我发现特征平台的能力可以满足多个层次的需求。我称之为「特征平台的需求层次」,我将逐层介绍这些需求,并讨论业界的特征平台为满足该层次需求所做的实践。
特征平台的需求层次
马斯洛需求层次理论是一个心理动力理论,认为人类有五个层次的需求,呈金字塔形。该理论认为,人会首先满足最大最基本的需求(金字塔底),才会考虑更高层次的要求(金字塔顶)。
关于「马斯洛需求层次理论」

(图注:马斯洛的需求层次金字塔,底层代表基本需求。来源)
生理需求:是生存所必需的,例如空气、水、食物、住处等。不满足这个需求,人类身体将无法正常工作。只有满足了这一最重要的需求,才会考虑其它需求。
安全需求:在生理需求被满足的前提下,需要保障安全,包括人身安全、健康、经济安全、就业、法律秩序、社会稳定等。这一需求通常由家庭、社会和政府满足。
社交需求:感到社会群体对自己的认可和接受。这类群体包括同事、教友、职业机构、体育俱乐部、在线社区等,也包括家庭、朋友和导师。
尊严需求:基于能力和成就。较低层次的尊严需求来自他人,包括他人的尊重认可和在其他人中的声誉。较高层次的尊严需求来自自己,包括对自己的尊重和内在的成就感。
自我实现需求:最高层的需求,是个人潜力的完全实现。对自我实现的需求因人而异。有的人希望成为完美父母,而有的人强烈希望在经济上、学术上、体育上取得成功。人们通过发明、艺术、写作等方式表达这种需求。
同样,特征平台会首先满足最必要和急迫的需求(包括特征读取和特征服务),再去考虑高阶需求。
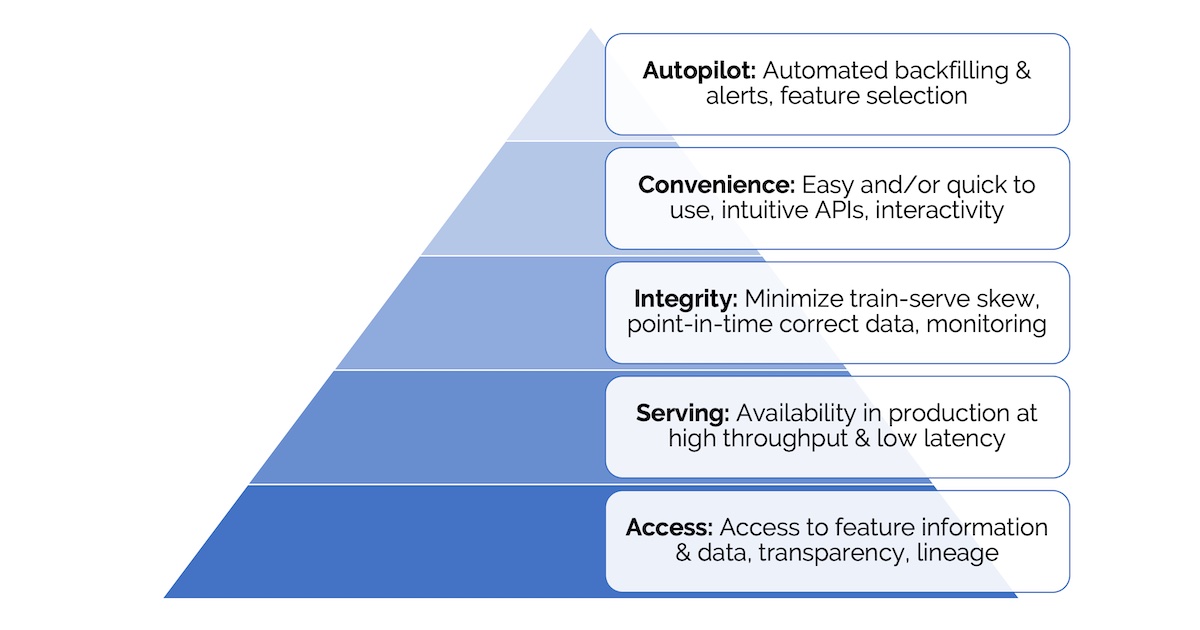
(图注:特征平台需求层次)
最底层是访问(access)的需求。这一层需求包括特征可读取、特征转换逻辑透明和特征血缘可溯。它们使得特征能被发现、分享和复用,减少重复。
从前,算法工程师进行机器学习开发时,60%的时间都花在编写特征转换逻辑上。—— Airbnb
其次是服务(serving)的需求。这一层的核心需求是为线上服务提供高吞吐、低延迟的特征读取能力,而无需通过 SQL 去数据仓库读取。其它需求还包括:与已有的离线特征存储集成,使得特征能够从离线特征存储同步到在线特征存储(例如 Redis);实时的特征转换等。
通常,数据工程师会将数据科学家实现的特征重新实现为可以在生产环境运行的特征管道。这个重复实现的过程会让项目推迟数月交付,让跨团队合作极为复杂。—— GoJek
两个底层需求被满足后,我们诉诸准确(integrity)需求。最常见的需求是最小化 train-serve skew,确保特征在训练和服务环境下是一致的。另一个常见需求是 point-in-time correctness(又称 time-travel),以确保历史特征和标签被用于训练和评估时不存在 data leaks。
训练通常是离线的,而服务通常是实时的。保证训练和服务环境下的数据一致性极为重要。—— Uber
再往上,是便利的需求。特征平台需要足够简单好入手,例如提供简单直观的接口、易交互、易 debug 等,才能让大家采纳和受益。
记住,我们是个平台组。我们要搭建工具把提供给用户,让他们能够自己动手丰衣足食。—— Uber
最后是自治(autopilot)的需求,包括自动回填特征、对特征的分布进行监控和报警等。我知道有些公司有做这一层的事情,但我没怎么读到相关材料。
特征回填是训练集迭代最主要的瓶颈。解决这一问题能极大地加速数据科学家的工作流。—— Airbnb
并非所有团队都有全部五层需求,对大部分团队而言,满足第一、二层和部分第三层的需求就很受益了。不同团队对于每一层需求的程度要求也不同。在线场景少的团队相比每秒需要处理几百万请求的的 DoorDash 团队,当然更少关心特征服务的需求;如果模型和特征每天更新多次,则更少需要关心 point-in-time correctness。
在逐层了解对特征平台的需求后,让我们来看看不同的公司是如何实现这些需求的。
对「创新者窘境」的借鉴
特征平台需求层次借鉴了「创新者窘境」所介绍的产品演进模型。
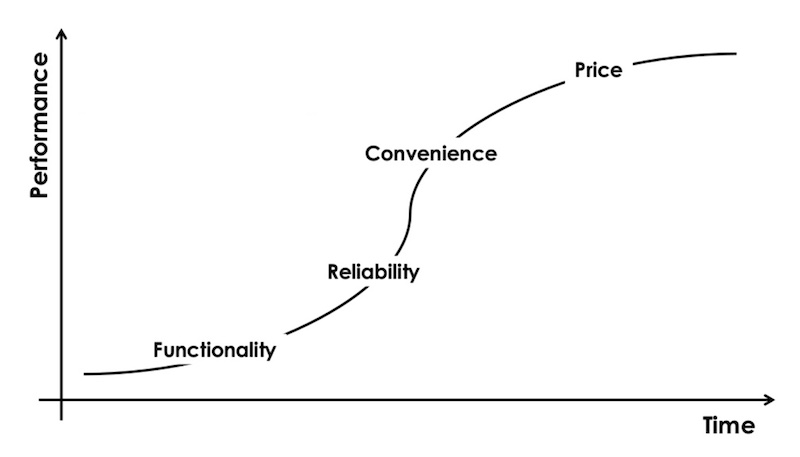
(图注:竞争的演进,从功能、可靠、便利到价格)
功能:当市场上没有一个产品满足功能方面的需求,竞争的基础在于功能。这款产品能否做到竞品做不到的事情?
可靠:当超过两个产品能满足功能的需求,消费者会选择更可靠的产品。这款产品质量是否稳定?
便利:当多个产品能满足可靠的需求,消费者会选择更便利的产品。这款产品是否容易使用?
价格:最终,当多个产品都能满足便利的需求时,竞争的基础转移到价格上。这款产品是否更便宜?
访问:去重和复用
如果特征难以访问,以下情况会发生:
- 不同团队反复实现同一个特征,导致同一特征可能有多达 10 个版本。
- 部署多个相近的特征管道,浪费计算和存储资源。
- 因为同一特征有多个版本,不同模型会使用不同版本的特征,很难得到一致的结果。
- 迭代变慢。
表达同一业务概念的特征被多个团队反复开发,已有工作无法复用。—— GoJek
为了解决这一问题,GoJek 搭建 Feast 作为数据工程师、数据科学家和算法工程师合作的接口。数据工程师和数据科学家创建特征,并提交给特征平台。随后,算法工程师消费特征,而无需自己创建。
(我很难评价这种做法,因为我认为数据科学家应该端到端。当然,GoJek 的做法或许和组织架构有关,因为它的数据工程团队主要在印度,而算法团队主要在新加坡。Feast 扮演了团队间沟通的接口。)
Uber 也采用了相似的做法,通过搭建 Palette 特征平台,鼓励不同部门分享和复用 Palette 中的特征。这种做法最小化了重复工作,让机器学习的的结果更加一致,加速机器学习的进程。
特征的可发现性使得特征易于发现和使用。我没有读到多少特征平台语境下的可发现性的相关讨论,估计它和我之前写过的开源数据发现平台很相似。
在这个层次上,特征平台基本上是个包含很多特征的存储,和数据仓库的区别不大。把两者区分开的是特征平台还能满足特征下一层次的服务需求。
服务:在实时环境使用特征
我们常用批数据离线训练模型,然而在线模型服务需要实时读取这些特征。这难住了很多团队——应该如何为在线模型服务高吞吐、低延迟地提供(serve)这些特征?
我们在开发模型的过程中发现:很多用于训练的特征,并无法在生产环境中获取。—— Monzo Bank
Monzo Bank 能从离线分析环境(用于模型训练)中获取特征,但无法从生产环境(用于模型服务)中获取特征。Monzo Bank 采用了一个轻量的解决方案,将离线分析存储(BigQuery)中的特征同步至在线存储(Cassandra)。
- 首先,在离线分析环境的 SQL 建表语句中加入标签。这些表的更新频率在小时或天级别。
- 特征平台中的 Go 服务检查特征表 schema 的正确性,例如必需的
subject_type和subject_id列是否存在。 - 有个 cron job 监听特征表的更新,将数据变动从 BigQuery 经过 Google Cloud Storage 的中转同步至 Cassandra。
Uber 的 Palette 采取了类似的双存储设计。离线存储(Hive)保存特征快照,用于训练。在线存储(Cassandra)实时提供同样的特征。特征由 Flink 生成,写入 Cassandra。两个存储之间会进行特征同步:添加到 Hive 的特征会被复制到 Cassandra,添加到 Cassandra 的特征会被 ETL 到 Hive。
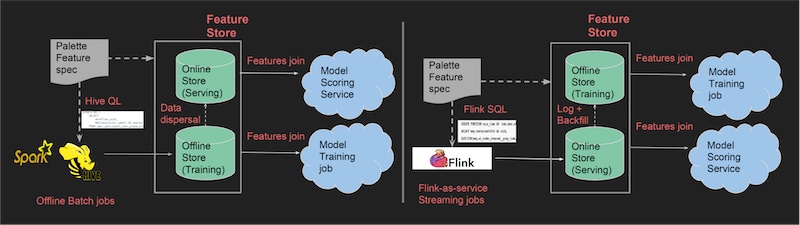
(图注:创建批特征(左边)和实时特征(右边),并在存储间同步。来源)
DoorDash 搭建了超大规模的特征平台,将特征服务做到极致,满足以下需求:
- 支持在可持久、可伸缩的存储中保存十亿级别条数的特征。DoorDash 有百万级别的特征实体(entity)和十亿级别的特征。
- 支持百万级别 QPS(Queries per second)。特征平台有多个使用场景,其中包括餐厅排序。这一场景使用大量特征,每秒做出超过一百万次预测。综合来看,特征平台的 QPS 超过一千万。
- 支持非实时特征每日一次的快速批更新,和实时特征(例如餐厅过去 20 分钟的平均送餐时长)一天内不断的更新。
DoorDash 在评估了 Redis、Cassandra、CockroachDB、ScyllaDB 和 YugabyteDB 后,选择了 Redis。这篇好文介绍了 DoorDash 的评估过程和针对 Redis 做的后续优化。
另一个方法是实时计算特征。例如,阿里巴巴的特征服务平台实时计算用户行为特征的统计量(点击、点赞、购买等),用于「猜你喜欢」实时推荐。这篇文章介绍了更多实时推荐的内容。
准确:创建正确的在线和离线特征
在满足服务的需求后,我们来看准确需求。准确性解决的主要痛点是:
- 难以创建 point-in-time correct 的特征,用于模拟生产环境。做不对的话,会导致 data leaks。
- 训练和服务环境特征的不一致,导致模型上线后表现欠佳。
为了解决第一个痛点,Netflix 实现了分布式 time-travel。它给离线和在线数据建立快照,快照内容包含成员类型、设备、当天时间等。
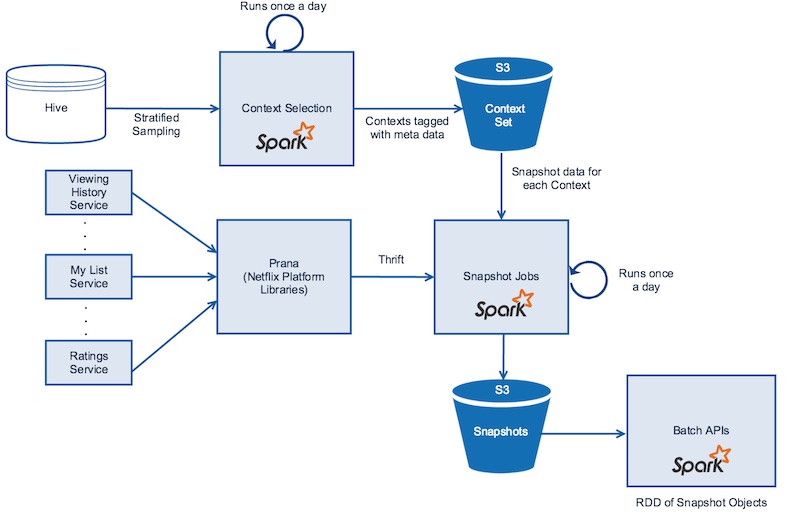
(图注:从离线和在线的微服务创建快照。来源)
然而,为每一个 context 都建立快照的成本很高。因此,Netflix 对观看模式、设备类型、设备使用时长、地区等离线特征进行分层抽样,这些样本很好地代表了用于模型训练和评估的数据的分布。抽样通过 Spark 完成,快照存储在 S3 中。
Netflix 也会对在线特征建立快照。数据产生自数百个微服务,数据包括观看历史、个性化观看列表、评分预测等。数据由 Spark 通过 Prana 并行获取,制成快照,以 Parquet 格式存储在 S3 上。
为了解决 train-serve skew 这第二个痛点,GoJek 用 Apache Beam 实现数据处理管道,消费来自批和流数据源(例如 BigQuery 和 Kafka)的数据,注入离线和在线存储(例如 BigQuery 和 Redis),并提供统一的接口来读取历史和实时数据。这种做法避免了因在生产环境重写特征管道而引入 train-serve skew。
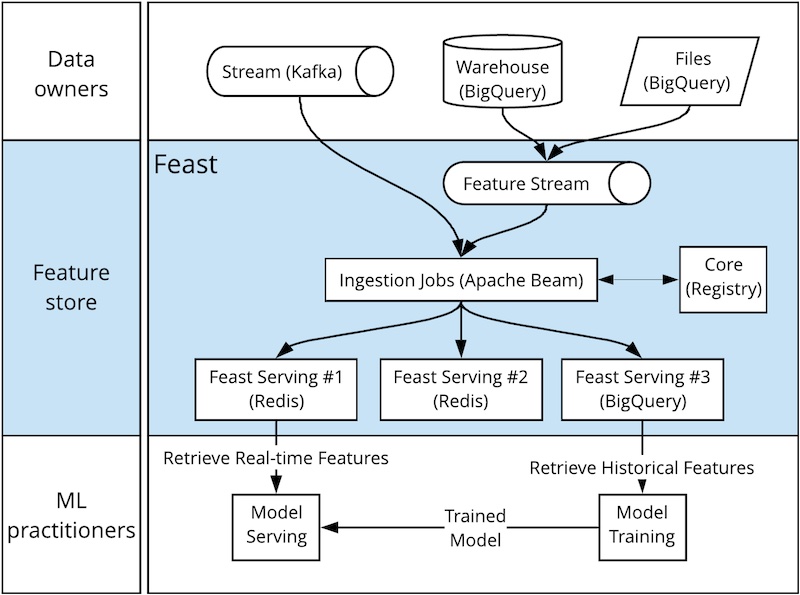
(图注:GoJek 基于 Apache Beam 的特征注入。来源)
Netflix 则通过共享的特征编码器(encoder)解决这一痛点。尽管他们在离线(Spark)和在线环境实现了不同的特征生成管道,但不同管道共用特征编码器(即同样的类、库和数据格式)。这也保证了特征生成过程在训练和服务环境的一致性。
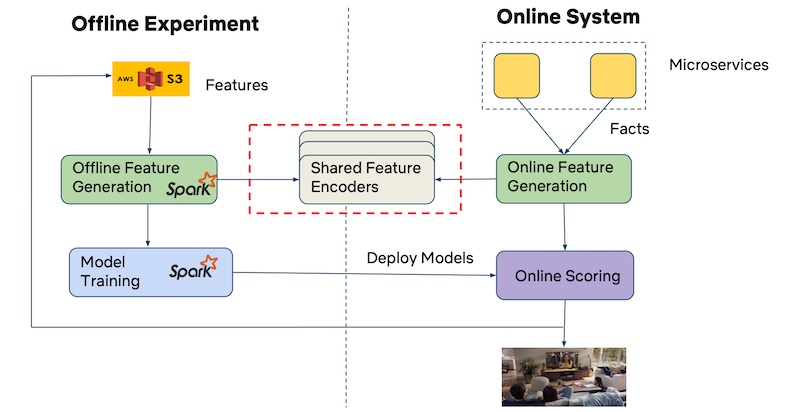
(图注:Netflix 的离线和在线特征生成使用同一个编码器。来源)
我们在前文介绍过 Uber 如何保持离线(Hive)和在线(Cassandra)特征存储的数据同步。任意一个存储的新特征都会被复制到另一个存储,确保训练和服务环境中数据的一致性。
为确保特征的准确,还需引入监控,回答以下问题:
- 特征最近一次更新是什么时候?
- schema 正确吗?数据分布发生了偏移吗?
- 特征服务达到了吞吐和延迟的要求吗?
Airbnb Zipline UI 向数据科学家展示特征的分布、特征和标签之间的相关性、聚类分析(尚不清楚基于什么做聚类分析)。类似地,Uber Data Quality Monitor 通过以下方法给用户展示每日数据质量分数和异常报警:
- 首先,搜集特征的指标,例如数值特征的均值、中位数、最大值、最小值,以及类别特征的唯一值个数和缺失值个数。
- 其次,基于指标建立多维时间序列,使用主成分分析(PCA)选取出要保留的主成分。
- 最后,使用主成分建立时间序列。如果当前测量值和上一步的预测值不匹配,则将该特征标记为异常。
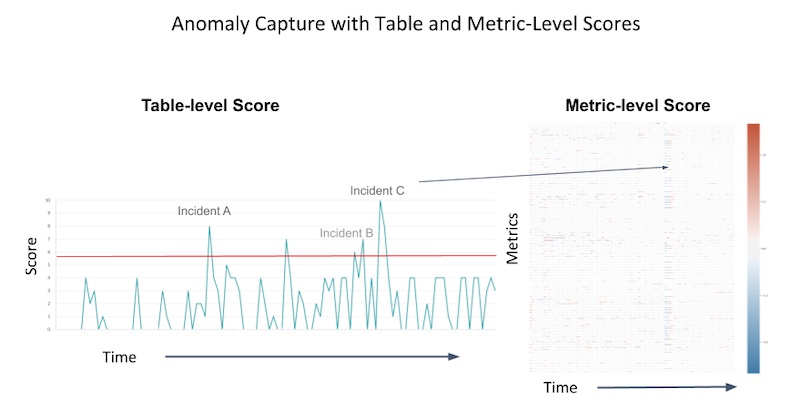
(图注:数据质量随时间的变化,以及当事故发生时。来源)
便利:尽量简单
当前,关于特征平台的便利需求,讨论并不多。但显然,好用的工具和平台非常重要(想想 PyTorch 和 Tensorflow 的对比)。
我找到的最好的例子来自 GoJek。GoJek 实现提供了统一的 Python、Java 和 Go SDKs,让用户可以在不同语言中几乎无区别地使用 get_batch_features() 和 get_online_features() 接口,简化从离线存储和在线存储中获取特征的过程。
customer_features = ['credit_score', 'balance', 'total_purchases', 'last_active']historical_features_df = feast.get_historical_features(customer_ids, customer_features)model = ml.fit(historical_features_df) # pseudo codeonline_features = feast.get_online_features(customer_ids, customer_features)prediction = model.predict(online_features)此外,Netflix 实现了简单的接口,让数据科学家能够容易地创建 point-in-time correct 和特征和标签。下面的例子展示如何读取电影 OUTATIME 的观看历史快照。
val snapshot = new SnapshotDataManager(sqlContext) .withTimestamp(1445470140000L) .withContextID(OUTATIME) .getViewingHistory基于该快照,用户只需提供以下内容,即可进行 time-travel,创建用于训练和评估的特征:
- 上下文:模型在何地何时被如何使用,例如国家、设备、成员档案、电影、时间等,其中时间非常关键。
- 物品:要评分或排序的物品,例如电影、推荐名单、搜索项等。
- 标签:监督学习的目标,例如点击、已看、观看分钟数等。无监督学习不需要这些内容。
- 特征编码器:如何将上下文和物品组合起来创建特征,例如国家-电影、用户 ID-电影等。
Uber Palette 的 DSL(含代码示例)
Uber 也详细介绍了他们如何通过拓展 Spark Transformer 和创建 DSL,进行特征读取和转换。
- Transformer:主要用于特征读取。
- Estimator:主要用于创建特征,而不是像 Spark Estimator 一样用于模型训练。
下面展示如何读取一个餐厅的特征。首先,从离线和在线特征存储中读取特征,并读取属性(可能来自事实表)。它们包括:订单数、准备时长、经纬度。
tx_p1 = PaletteTransformer([ "@palette:restaurant:realtime_feature:nMeal:r_id", "@palette:restaurant:batch_feature:preptime:r_id", "@palette:restaurant:property:lat:r_id", "@palette:restaurant:property:log:r_id",])其次,estimator 通过经纬度获知餐厅的地区 ID。
es_dsl1 = DSLEstimator(lambdas=[ ["region_id", "regionId(@palette:restaurant:property:lat:r_id, @palette:restaurant:property:log:r_id)"]])然后,通过地区 ID 这一特征,可以获知该区域的忙碌程度。
tx_p2 = PaletteTransformer([ "@palette:region:service_feature:nBusy:region_id"])最后,进行一些额外的特征处理,包括用均值来推算准备时长,将特征转化为数值等。
es_dsl2 = DSLEstimator(lambdas=[ ["prepTime": nFill(nVal("@palette:restaurant:batch_feature:prepTime:r_id"), avg("@palette:restaurant:batch_featuer:prepTime:r_id"))], ["nMeal": nVal("@palette:restaurant:realtime_feature:nMean:r_id")], ["nOrder": nVal("@basis:nOrder")], ["nBusy": nVal("@palette:region:service_feature:nBusy:region_id")]])DSL 为特征读取和转换提供了一个抽象层,让用户可以很容易地在规定范围内使用。但我不清楚如何在不执行的前提下验证 DSL 的正确性,也不确定 DSL 是否容易定制化拓展。
自治:尽量自动
最顶层是自治需求。自治可以降低开发难度和运维成本,否则数据科学家需要花时间进行枯燥的手动操作。目前,有些公司分享了相关经验,但自治在业界还不普遍。
Airbnb 发现数据回填成为数据科学家迭代模型实验的瓶颈。因此,Zipline 支持自动特征回填。数据科学家可以在简单的 UI 上定义新特征,指定开始和结束日期,以及回填任务的并行进程个数,随后这些特征就会通过 Airflow 管道添加到到已有的训练特征集中。
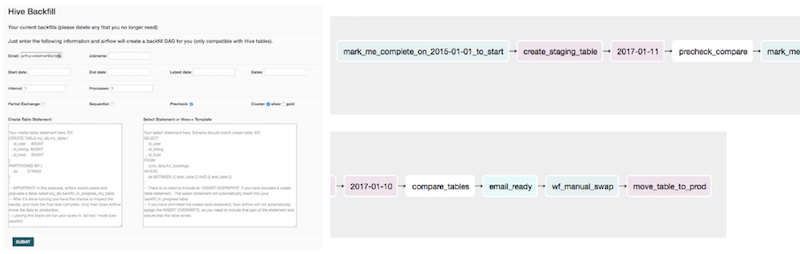
(图注:Airbnb 特征回填 UI,和它所创建的 Airflow DAG。来源)
下面是自治方面的其它实践:
- Netflix Metacat 提供了特征表的成本和存储空间指标,便于删除不用的特征表,节约成本。
- Uber Data Quality Monitor 进行自动的异常检测,基于数据质量指标和每日数据质量分数进行通知。
- Uber 实验支持自动特征选择。用户只需提供要预测的标签,Palette 就能推荐出与标签有关的特征。
总结:取决于你的需求
我希望现在大家对「特征平台是什么」有了更清晰的理解。如果我们从零开始,我们所需的不过是访问和服务,加上一点点准确性。如果我们在大厂搭建特征平台,则需更早考虑便利和自治。如有问题,欢迎联系 @eugeneyan !
想开始搭建特征平台吗?Feast 是个不错的选择。它满足了访问和服务的需求,并提供了一致的接口,让训练和服务可以使用相似的代码。最棒的一点是,它是开源(免费)的。不妨告诉我进展如何!
参考文献
[1] Feature Stores - A Hierarchy of Needs. https://eugeneyan.com/writing/feature-stores/
[2] Rethinking Feature Stores. https://medium.com/data-for-ai/rethinking-feature-stores-74963c2596f0
Feedback is a gift! Please send your feedback via email or Twitter.
© Yik San Chan. Built with Vercel and Nextra.