DoorDash 预测服务实践
本文同步发表在伴鱼技术博客。
前言
本文是「算法工程化实践选读」系列的第 4 篇,选读 DoorDash 在 2020 年 6 月发布的技术博客 Meet Sibyl – DoorDash’s New Prediction Service – Learn about its Ideation, Implementation and Rollout。它介绍了预测服务 Sibyl(希腊神话中著名的女先知)的架构和发布过程。
架构
一个典型的机器学习预测服务要做的事情很简单:将模型加载好,根据请求信息,获取相关特征,将特征输入匹配的模型,得到预测结果并返回。
那么,我们能不能搭建一个预测服务,它能一致地处理所有的预测请求,并确保总能低延迟地返回预测结果呢?DoorDash 的预测服务 Sibyl 用下图这个简单的架构实现了这个需求。
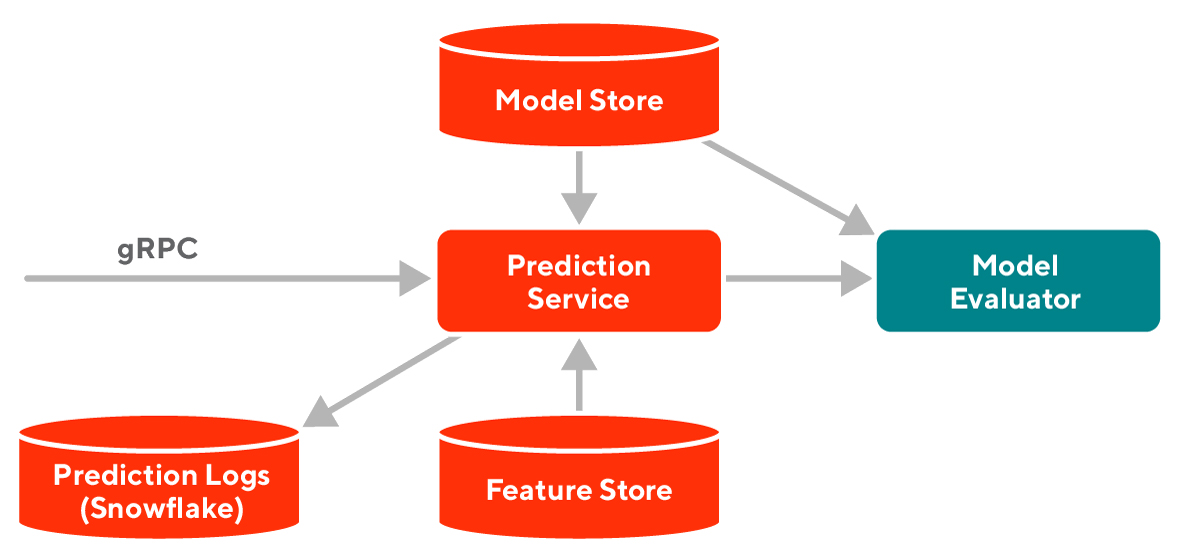
让我们逐个模块来看:
- 预测服务(Prediction Service)管理预测请求的整个生命周期。
- 模型仓库(Model Store)负责模型的存储。模型以原生格式存储,以便优化预测的性能。
- 特征平台(Feature Store)提供特征。
- Model Evaluator 负责模型推理。它通过 JNI 调用由 C++ 实现的 LightGBM 和 PyTorch 的预测请求,优化预测性能。在 Sibyl V1 中,Model Evaluator 被包含在 Sibyl 内,但在后续版本中,这个模块会独立成一个服务。
- Snowflake 数据湖存储预测服务产生的预测日志(Prediction Logs),用于后续模型监控,参考这篇博客。
基于这样一个架构,一个 Sibyl 预测请求的生命周期如下:
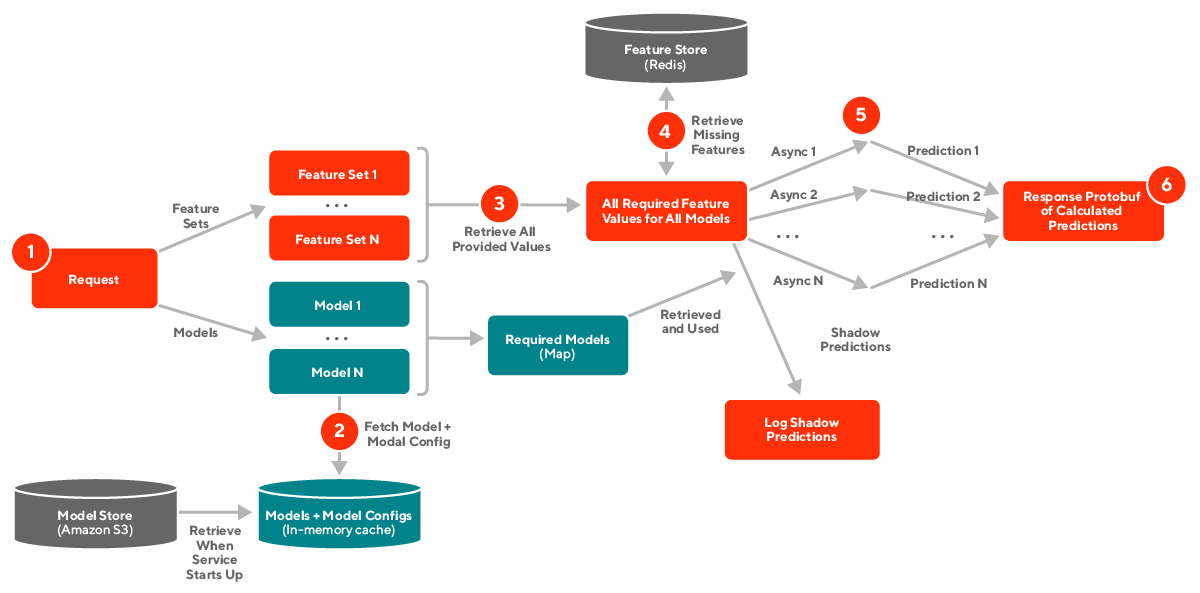
- 请求抵达服务。
- 识别请求需要的模型,从缓存中读取模型和模型配置。模型配置包括模型所需的特征、特征的默认值、模型类型等。
- 看请求提供了哪些特征,缺了哪些特征。
- 对于缺失的特征,从特征平台读取特征值。如果依旧缺失,则使用模型配置提供的特征默认值。
- 对于每一批特征,用 coroutine 异步执行预测请求。
- 将响应返回给请求方。
发布过程
Sibyl 选择了 DoorDash App 的「搜索」作为切入点。当时,搜索服务遇到的问题是,内置的排序服务占用了搜索服务大量的 RAM 和 CPU,排序模型的进一步迭代非常受限。
Sibyl 团队选择的做法是,每当 app 向搜索服务发送请求,它会同时向 Sibyl 发送一个请求,但不期待响应,称为影子请求。这种做法能验证 Sibyl 是否能返回正确的预测结果,并能处理这么高流量的请求。最终,Sibyl 能处理的 QPS 达到 10 万级别。下一步是不是该在生产环境中用 Sibyl 来取代搜索服务的排序部分了?
不是。原因在于搜索服务对延迟的要求很严格,且把搜索有关的特征全部迁移到 Sibyl 对接的特征平台也需要时间。于是 Sibyl 团队选择了流量和延迟性要求都更低的「诈骗检测」和「骑手支付」,作为最早在生产环境上切换到 Sibyl 的模型。结果不错,预测延迟降低了 3 倍。
此后,绝大多数模型都完成了向 Sibyl 的迁移,包括「搜索」。这篇文章介绍了搜索服务接入 Sibyl 的细节。
总结
将所有预测请求的处理集中在一个预测服务的做法,大大简化了架构,使得无需为每个模型单独实现一个预测服务;但这也对集中的预测服务的可用性提出了特别高的要求。总的来看,利大于弊,团队需要克服技术上的挑战,收获先进架构带来的效率提升。
此外,我有几个疑问:
- 复杂推理的耗时可能较长,Sibyl 是如何处理这种情况,是否需要在 Model Evaluator 引入预计算?
- 如果引入预计算,预计算部分的架构是怎么样的?
Feedback is a gift! Please send your feedback via email or Twitter.
© Yik San Chan. Built with Vercel and Nextra.